MIT 6.5840 Lab5:Sharded KV
顺序:Lab1 MapReduce / Lab2 KV Server / Lab3 Raft / Lab4 KV over Raft / Lab5 Sharded KV
一句话总结
Lab5 把单一 Raft Group 扩展为多个 Raft Group,每个 Group 负责一部分 Key(分片),并且支持动态迁移——加减节点时数据能自动搬家。
为什么要做这个
Lab4 的 KV 服务有一个致命问题:所有数据都在一个 Raft Group 里。
- 写入瓶颈:所有写都要经过唯一的 Leader
- 存储瓶颈:所有数据存在每台机器上
- 扩展方式:只能加副本(提高容错),不能加容量
分片(Sharding)解决了这个问题:把 key space 分成 N 份,每份由不同的 Group 负责。
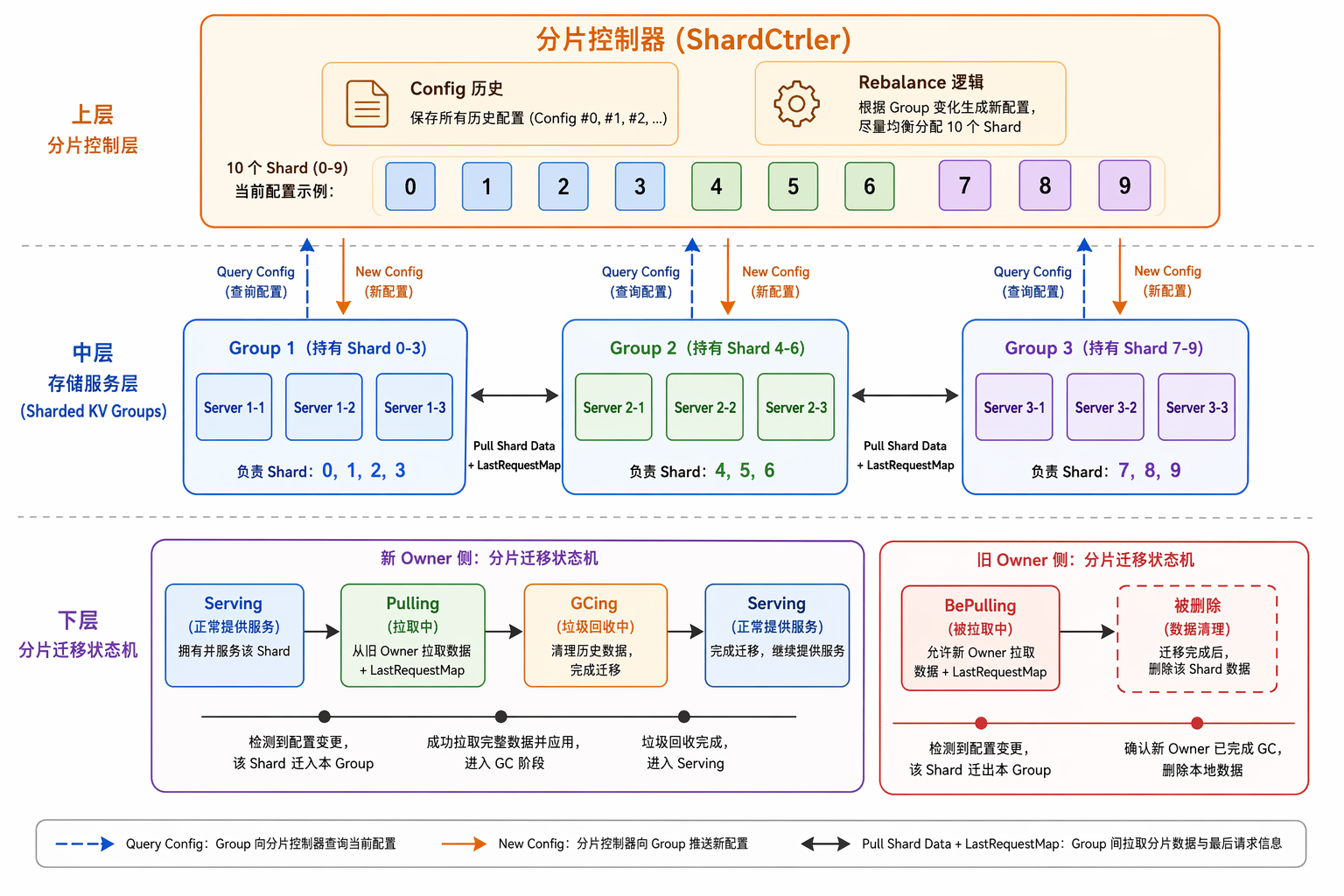
整体架构
1 | ┌──────────────────────────────────────────────────────────┐ |
- ShardCtrler:集中式配置管理,本身也是 Raft 复制的
- Group:每个 Group 是一个独立的 Raft 集群,负责若干 Shard
- Shard:key 通过
key[0] % NShards映射到 Shard 号
Lab5A:ShardCtrler
ShardCtrler 管理配置的变迁历史:
1 | type Config struct { |
四个操作:
| 操作 | 作用 | 触发 Rebalance? |
|---|---|---|
| Join(groups) | 新增 Group | 是 |
| Leave(gids) | 移除 Group | 是 |
| Move(shard, gid) | 手动指定某 Shard 归属 | 否 |
| Query(num) | 查询某版本配置 | 否 |
Rebalance 算法
目标:让每个 Group 负责的 Shard 数量尽可能均匀(差值 ≤ 1)。
1 | func adjustShards(shards *[10]int, groups map[int][]string) { |
关键细节:排序保证确定性。Go 的 map 迭代顺序是随机的,如果不排序,不同副本可能算出不同的分配结果!
Lab5B:Sharded KV
这是整个课程最复杂的 Lab。核心挑战:配置变更时,数据如何安全迁移?
分片四状态机
每个 Shard 在每个 Group 上有四种状态:
1 | Config 变更 |
状态转换的含义:
- Serving:正常服务,接受 Client 请求
- Pulling:我是新 Owner,正在从旧 Owner 拉数据,暂不接受该 Shard 的请求
- BePulling:我是旧 Owner,等待新 Owner 来拉我的数据
- GCing:数据已拉到,但还没通知旧 Owner 删除
为什么用 Pull 而不是 Push?
如果旧 Owner 主动 Push:
- 旧 Owner 挂了 → 数据卡在半路,新 Owner 不知道什么时候能收到
- 需要额外的重试和确认机制
如果新 Owner 主动 Pull:
- 旧 Owner 挂了 → 新 Owner 重试即可
- 主动权在需要数据的一方,逻辑更简单
三个后台 Monitor
只在 Leader 上运行的三个 goroutine,驱动整个迁移流程:
1 | // Monitor 1:拉取新配置 |
配置升级必须逐步进行
核心约束:所有 Shard 必须全部处于 Serving 状态,才能开始拉取下一个配置。
1 | func (kv *ShardKV) allShardsServing() bool { |
为什么?假设跳过了中间配置:
- Config 1: Shard 3 在 Group A
- Config 2: Shard 3 从 A → B
- Config 3: Shard 3 从 B → C
如果 C 直接从 Config 1 跳到 Config 3,它去找 A 拉数据。但 A 可能已经按 Config 2 把数据给 B 了!
迁移的完整流程
以 Shard 3 从 Group A → Group B 为例:
1 | 时间轴 → |
去重表也要跟着迁移
1 | type ShardData struct { |
为什么?假设 Client X 的 Append 请求被 Group A 执行了。Shard 迁移到 Group B 后,如果 Client X 重试(因为没收到回复),Group B 必须知道这个请求已经执行过。
合并去重表时取 max:
1 | for clientId, requestId := range incomingLastRequestMap { |
所有内部操作走 Raft
配置变更、Shard 插入、Shard 删除、状态调整——这些全部作为命令通过 Raft 提交:
1 | type Command struct { |
这保证了 Group 内所有副本看到完全相同的状态变迁序列。如果只在 Leader 本地执行这些操作,Leader 切换后新 Leader 的状态可能和 Follower 不一致。
Client 的视角
Client 完全不需要知道迁移的细节:
1 | func (ck *Clerk) Get(key string) string { |
收到 ErrWrongGroup 时,Client 向 ShardCtrler 查询最新配置,然后重试。整个迁移过程对 Client 几乎透明。
这个 Lab 的核心收获
- 分片是水平扩展的基础:把数据按 key 分到不同机器,每台只负责一部分
- 配置变更必须序列化:不能跳配置,否则数据可能找错 Owner
- Pull 优于 Push:主动权在需求方更容易实现容错
- 内部操作也要共识:状态变更必须经过 Raft,保证副本一致
- 去重表是业务状态的一部分:迁移数据时必须同步迁移去重表
这 5 个 Lab 从 MapReduce 走到 Sharded KV,构建了一个完整的分布式系统知识栈。每一层都在解决上一层遗留的问题,最终形成一个可扩展、容错、强一致的分布式 KV 服务。