MIT 6.5840 Lab3:Raft 共识算法
顺序:Lab1 MapReduce / Lab2 KV Server / Lab3 Raft / Lab4 KV over Raft / Lab5 Sharded KV
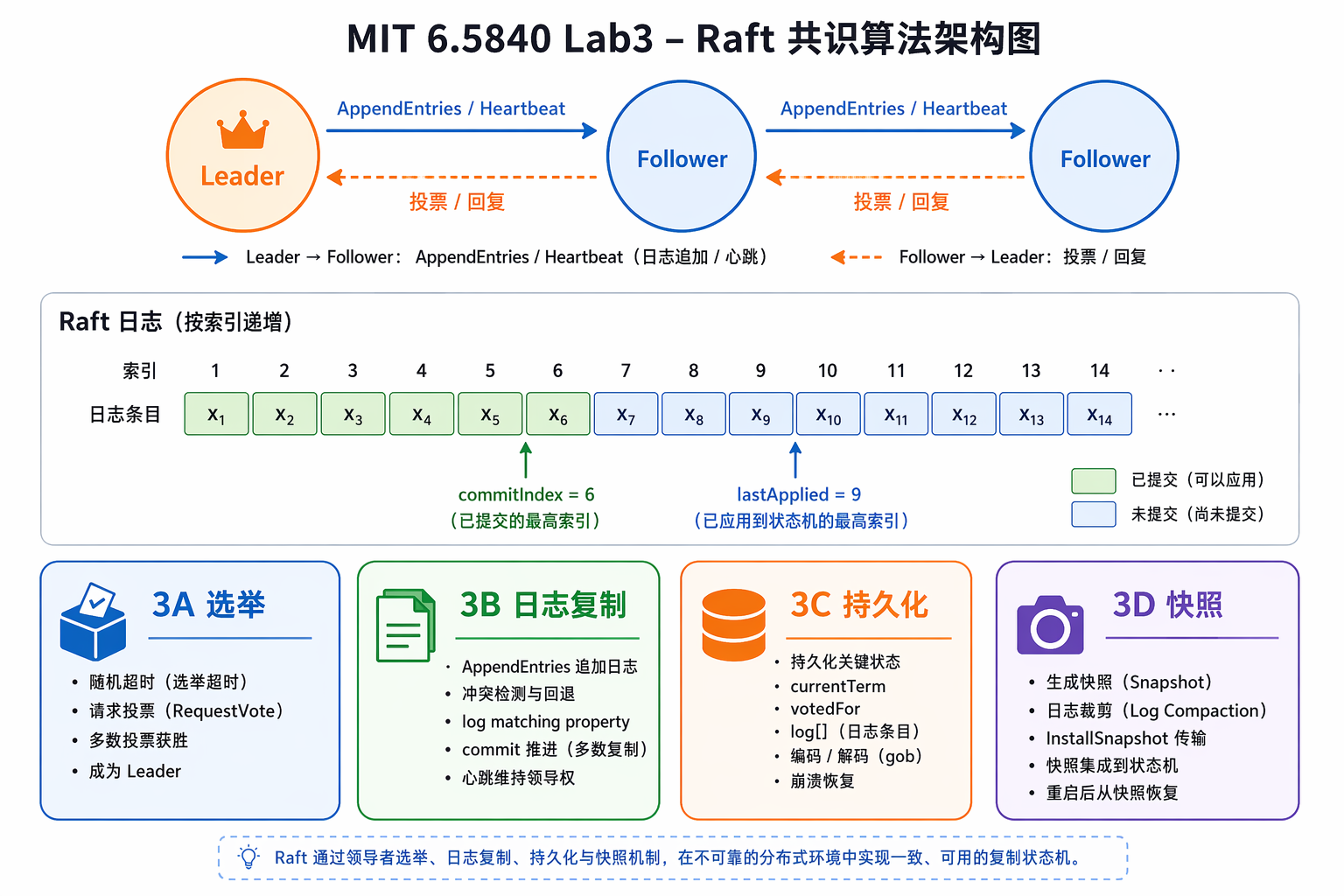
一句话总结
Lab3 实现完整的 Raft 共识算法——让多台机器对一组操作的顺序达成一致,即使部分机器挂掉也能继续工作。
为什么要做这个
单机 KV(Lab2)挂了就全部丢了。我们需要复制:把数据复制到多台机器上,挂掉少数几台也不影响服务。
但复制带来新问题:多台机器怎么保证对操作顺序的一致性?Raft 就是解决这个问题的算法。
一个比喻理解 Raft
想象一个公司:
- Leader:CEO,所有决策由它做出
- Follower:员工,听 CEO 的指挥
- Candidate:CEO 挂了后竞选新 CEO 的人
规则:
- 正常情况下只有一个 CEO,所有命令由它发出
- CEO 定期发心跳,证明自己还活着
- 员工超时没收到心跳,就开始选举新 CEO
- 得到多数票才能当选
Lab3A:Leader 选举
三种角色转换
1 | 超时 |
选举超时
1 | // 随机超时 [250ms, 400ms],避免所有节点同时发起选举(split vote) |
为什么要随机?如果所有节点超时时间相同,它们会同时发起选举,互相投票给自己,谁也选不上。
投票规则
不是谁先来就投给谁。要比较日志的新旧:
1 | // 候选人的日志至少要和我一样新,我才投票给它 |
这保证了:新 Leader 一定包含所有已提交的日志。
Term(任期)
Term 是 Raft 的”逻辑时钟”。规则很简单:
- 每次选举,Term +1
- 收到更高 Term 的消息 → 立即变成 Follower
- 收到更低 Term 的消息 → 拒绝
Lab3B:日志复制
Leader 选出来了,现在它要把客户端的命令复制给所有 Follower。
复制流程
1 | Client: Start(command) |
AppendEntries 的核心参数
1 | type AppendEntriesArgs struct { |
关键是 PrevLogIndex 和 PrevLogTerm——它们形成一个一致性检查:
“我要追加的新日志,接在 index=5, term=2 的后面。你那儿 index=5 也是 term=2 吗?”
如果不匹配,说明日志有分歧,需要回退重试。
冲突优化:按 Term 跳跃
朴素做法:nextIndex 每次减 1,可能要回退很多次。优化做法:
1 | // Follower 告诉 Leader 冲突 term 对应的第一条日志 |
Leader 直接跳到冲突 term 的起始位置,大大减少回退次数。
Commit 规则
Leader 只能提交当前 term 的日志(Figure 8 安全性):
1 | // 只有当 log[N].Term == currentTerm 时才能提交 index N |
Lab3C:持久化
哪些状态需要在 crash 后恢复?
| 状态 | 持久化? | 原因 |
|---|---|---|
| currentTerm | 是 | 防止在同一 term 投两次票 |
| votedFor | 是 | 同上 |
| log[] | 是 | 日志是数据的唯一来源 |
| commitIndex | 否 | 可以从日志和多数派重新推导 |
| lastApplied | 否 | 重启后从头 apply |
1 | func (rf *Raft) persist() { |
规则:任何修改 currentTerm/votedFor/log 的地方都必须调用 persist()。遗漏一处就可能导致数据不一致。
Lab3D:快照
问题:日志无限增长,内存会爆。解决:定期把状态机快照保存,然后裁剪已快照的日志。
日志裁剪
1 | 裁剪前:[1] [2] [3] [4] [5] [6] [7] [8] |
log[0] 永远是哨兵,存储 LastIncludedIndex 和 LastIncludedTerm,真正的日志从 log[1] 开始。
InstallSnapshot
当 Follower 落后太远(需要的日志已被 Leader 裁剪),Leader 直接发送整个快照:
1 | if rf.nextIndex[server] <= rf.getFirstIndex() { |
Follower 收到快照后:
- 替换整个日志前缀
- 保存快照到 persister
- 通过 applyCh 通知上层应用快照
实现中的坑
1. Apply 的顺序保证
用 sync.Cond 通知 apply goroutine,保证 commitIndex 推进后立即 apply:
1 | rf.commitCond.Signal() // commitIndex 更新后 |
如果用 sleep 轮询,会引入延迟,测试过不了。
2. Start() 后立即心跳
测试有速度要求。Client 调用 Start() 提交命令后,必须立即触发一轮心跳,不能等到下一个 100ms 心跳周期:
1 | func (rf *Raft) Start(command interface{}) (int, int, bool) { |
3. Figure 8 陷阱
新 Leader 不能通过计数来提交旧 term 的日志。必须先提交一条自己 term 的日志(哪怕是空的 noop),才能间接”带动”旧日志被提交。
这个 Lab 的核心收获
Raft 本质上就做一件事:让一组机器对日志序列达成一致。
- Leader 负责决定顺序
- 投票机制保证 Leader 有全部已提交数据
- Term 机制保证不会出现”脑裂”
- 持久化保证 crash 后不会”忘事”
- 快照保证日志不会无限增长
理解了这些,Lab4 就是在 Raft 之上搭一个 KV 服务而已。