顺序:Lab1 MapReduce / Lab2 KV Server / Lab3 Raft / Lab4 KV over Raft / Lab5 Sharded KV
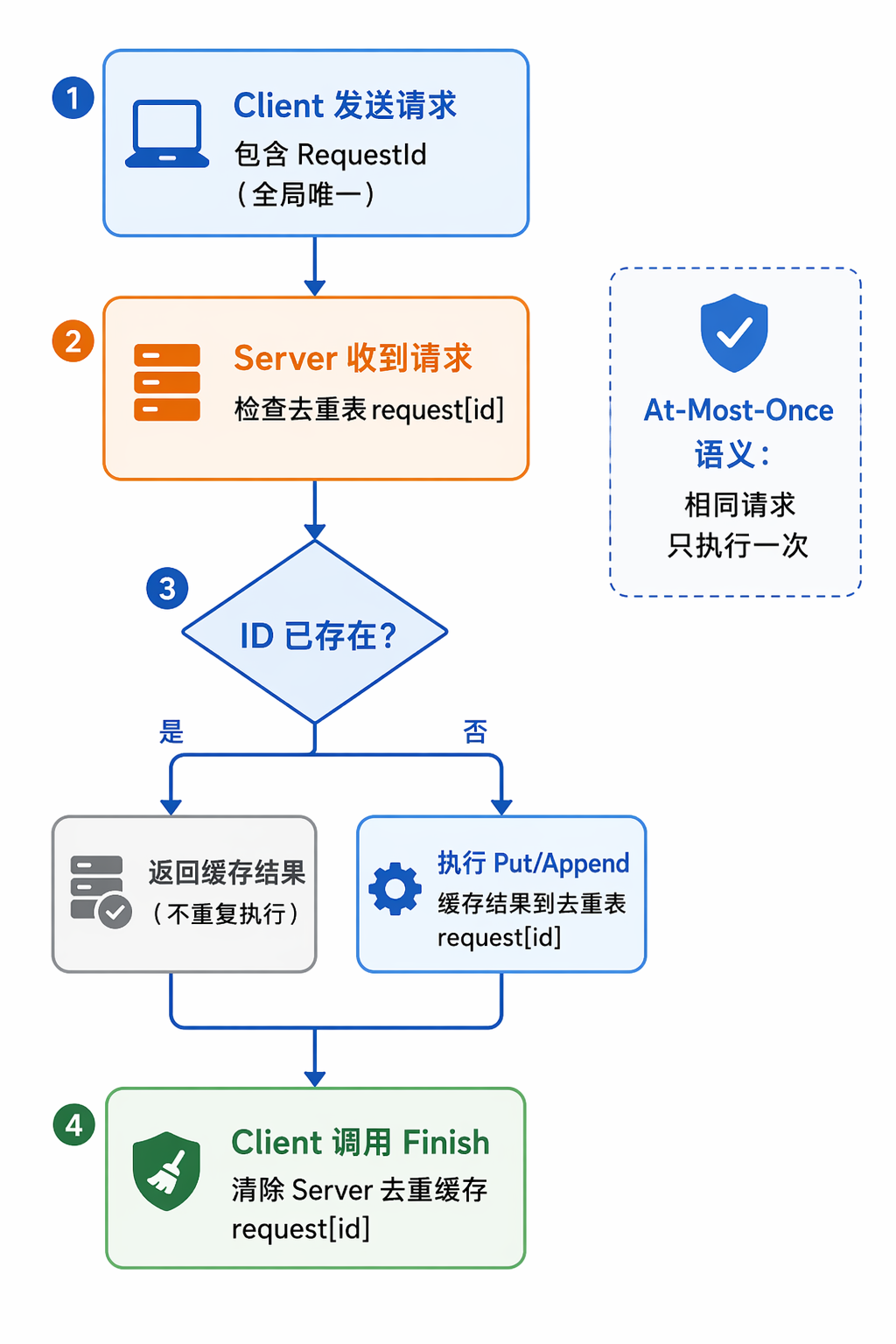 Lab2 的核心:Client 请求 → Server 去重检查 → 执行/返回缓存 → Client 确认清理。
Lab2 的核心:Client 请求 → Server 去重检查 → 执行/返回缓存 → Client 确认清理。
一句话总结
Lab2 在单个服务器上实现一个 KV 存储,核心挑战是在不可靠网络下保证每个请求最多执行一次(at-most-once)。
为什么要做这个
网络是不可靠的。Client 发了一个 Append("balance", "+100") 请求:
- Server 执行了,回复丢了 → Client 重试 → 余额多加了 100!
- 这就是”exactly-once”问题。
Lab2 教你如何用请求去重解决这个问题,这个模式会贯穿后面所有 Lab。
核心问题:重复请求
1
2
3
4
5
6
| Client Server
│── Put("x", "1") ────→ │ ✓ 执行,x="1"
│ │
│←── OK ─────────────── │ ← 这个回复丢了!
│ │
│── Put("x", "1") ────→ │ ← Client 重试,Server 怎么知道这是重复的?
|
如果 Server 不做任何处理,第二次请求会被当作新请求执行。对于 Put 还好(幂等),但对于 Append 就会重复追加。
解决方案:去重表
每个请求带一个全局唯一的 ID。Server 维护一张表记录已处理的请求:
1
2
3
4
5
| type KVServer struct {
mu sync.Mutex
data map[string]string
request map[int64]string
}
|
处理流程:
- 收到请求,先查
request[id]
- 如果存在 → 直接返回缓存结果,不再执行
- 如果不存在 → 执行操作,缓存结果
但是——内存会爆炸
去重表会无限增长!每个成功的请求都缓存着。解决方案是 Client 确认机制:
1
2
3
4
5
6
7
|
func (ck *Clerk) PutAppend(key, value, op string) string {
id := atomic.AddInt64(&globalId, 1)
ck.Finish(id)
return result
}
|
1
2
3
4
5
6
|
func (kv *KVServer) Finish(args *FinishArgs, reply *FinishReply) {
kv.mu.Lock()
delete(kv.request, args.Id)
kv.mu.Unlock()
}
|
三种操作的处理
| 操作 |
幂等? |
需要去重? |
说明 |
| Get |
是 |
否 |
读操作天然幂等,重复执行无影响 |
| Put |
是 |
否(但实际做了) |
覆盖写,结果相同 |
| Append |
否 |
是 |
追加写,重复执行会多加一次 |
严格来说只有 Append 需要去重,但实现中对 Put/Append 统一去重简化了逻辑。
Client 的设计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| type Clerk struct {
server *labrpc.ClientEnd
}
func (ck *Clerk) PutAppend(key, value, op string) string {
id := atomic.AddInt64(&id, 1)
args := &PutAppendArgs{Key: key, Value: value, Op: op, Id: id}
for {
reply := &PutAppendReply{}
ok := ck.server.Call("KVServer.PutAppend", args, reply)
if ok {
ck.Finish(id)
return reply.Value
}
}
}
|
关键点:同一个请求的所有重试使用相同的 ID。这样 Server 就能识别重复。
时序图:完整的请求生命周期
1
2
3
4
5
6
7
8
9
| Client Server
│ │
│── PutAppend(id=42) ────────→ │ 查 request[42]:不存在
│ │ 执行 Append,缓存 request[42]=result
│←── OK(result) ──────────── │
│ │
│── Finish(id=42) ──────────→ │ delete(request[42])
│←── OK ─────────────────── │
│ │
|
如果第一步的回复丢了:
1
2
3
4
5
6
7
8
9
| Client Server
│ │
│── PutAppend(id=42) ────────→ │ 执行,缓存 request[42]=result
│←── OK(result) ──── ✗ 丢了 │
│ │
│── PutAppend(id=42) ────────→ │ 查 request[42]:已存在!
│←── result(缓存值)──────── │ 不重复执行
│ │
│── Finish(id=42) ──────────→ │ 清除缓存
|
这个 Lab 建立的思维模式
- 不可靠网络是常态:任何 RPC 都可能丢失、延迟、重复
- 去重是幂等的基础:非幂等操作必须有去重机制
- Client 和 Server 要协作:只靠一方无法解决问题
后面的 Lab3/4/5 都会复用这套模式:ClientId + RequestId + 去重表。区别只是 Server 从单机变成了分布式。