TinyKV / TiKV / MIT 6.5840 面经索引
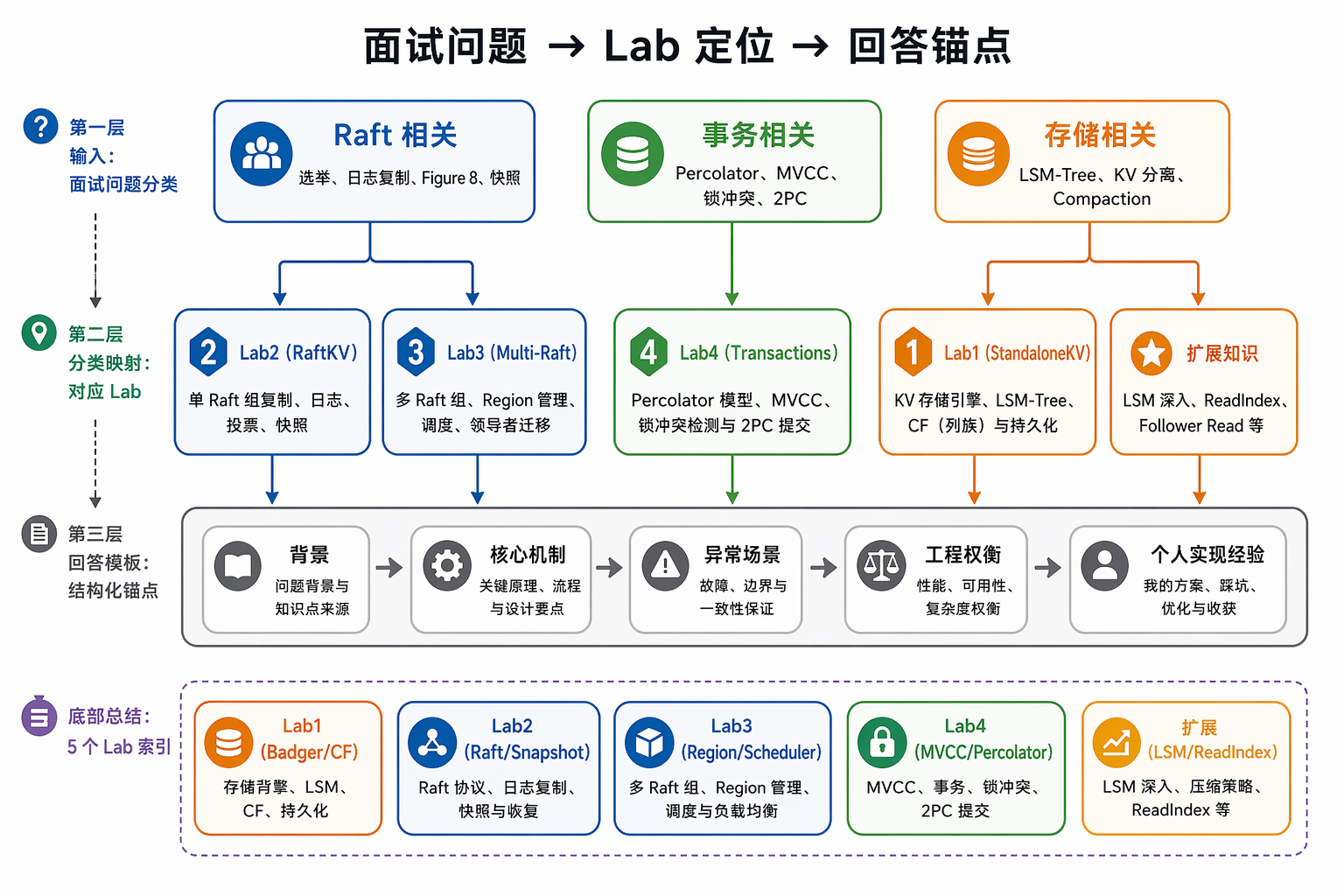
我把最近两年和 TinyKV、TiKV、MIT 6.824/6.5840 相关的面经单独拎出来了。牛客和个人博客权重最高,因为它们通常会记录逐轮问题;问答站和路线帖可以看,但不适合作为主证据。
看这张表的时候,重点不是背公司名字,而是找追问模式:Raft 会追异常场景,事务会追 Percolator 和锁清理,存储引擎会追 LSM/Badger,TinyKV 项目会追你到底改过哪些模块。
我把最近两年和 TinyKV、TiKV、MIT 6.824/6.5840 相关的面经单独拎出来了。牛客和个人博客权重最高,因为它们通常会记录逐轮问题;问答站和路线帖可以看,但不适合作为主证据。
看这张表的时候,重点不是背公司名字,而是找追问模式:Raft 会追异常场景,事务会追 Percolator 和锁清理,存储引擎会追 LSM/Badger,TinyKV 项目会追你到底改过哪些模块。
顺序:MIT 6.5840 和 TinyKV / Lab1 / Lab2 / Lab3 / Lab3B / Lab4 / 面经索引。
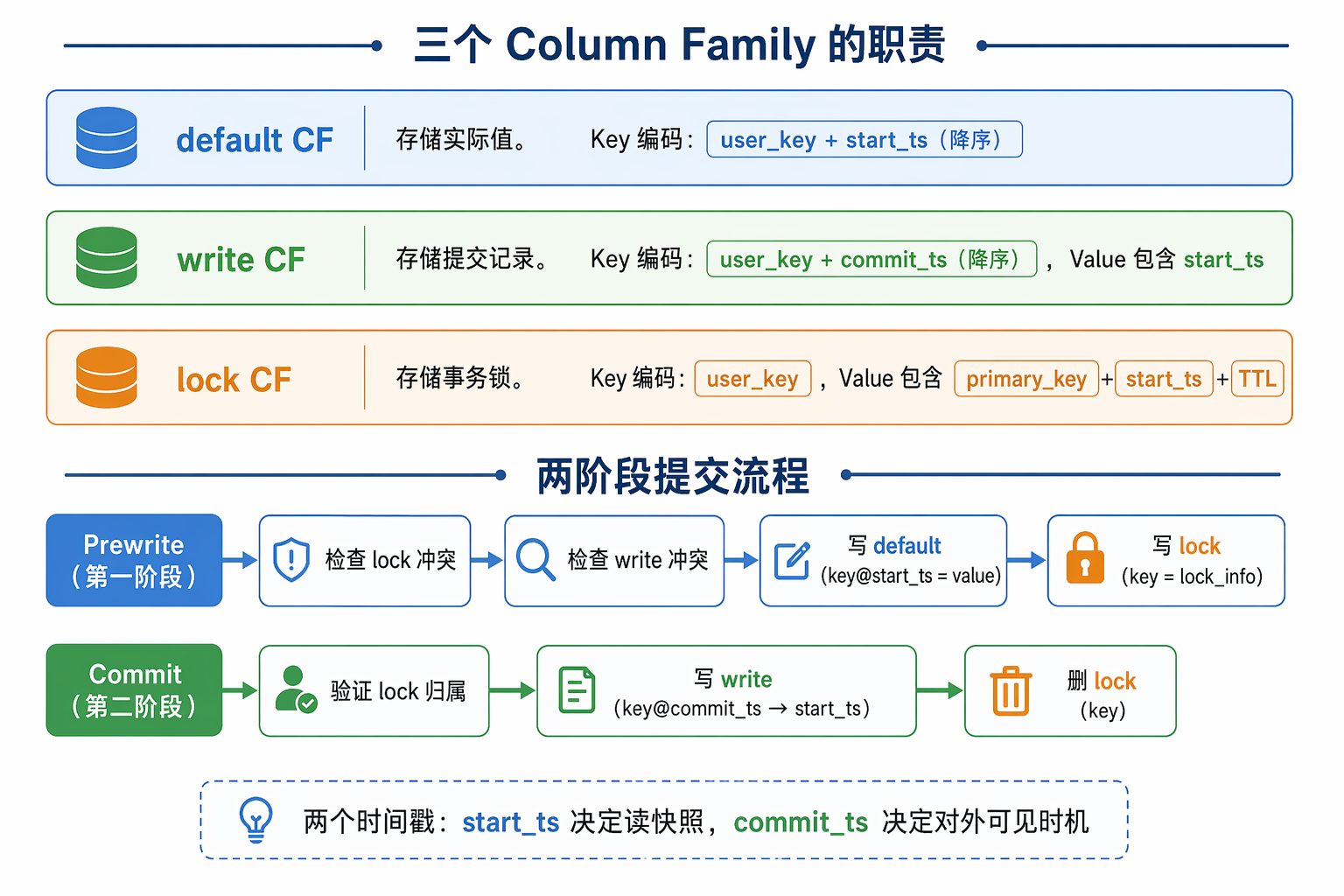
Lab4 的问题换了一类:前面几层关心数据怎么复制、怎么分片,这里关心并发事务怎么读到稳定快照、怎么发现写冲突,以及崩溃后怎么把遗留锁处理干净。
官方页面:https://github.com/talent-plan/tinykv/blob/course/doc/project4-Transaction.md
Lab4 不要一上来就背 MVCC、Percolator、2PC。先把它想成一个多人共用的小仓库。
Lab1 到 Lab3 已经让这个仓库越来越靠谱:
graph LR
L1["Lab1<br/>单机仓库<br/>能查、存、删、扫"] --> L2["Lab2<br/>多副本仓库<br/>写入先经过 Raft"]
L2 --> L3["Lab3<br/>很多片仓库<br/>按 Region 分摊 key 空间"]
L3 --> L4["Lab4<br/>事务仓库<br/>多人同时改也要有规矩"]
Lab1-3 解决的是:
1 | 数据怎么存 |
Lab4 解决的是:
1 | 多个客户端同时读写时,怎么保证读到一个稳定视图。 |
换成更生活化的话:
1 | Lab1-3 像是在建设仓库本身。 |
这就是 Lab4 的直觉。
graph TB
Raw["Lab1-3 的 Raw KV 视角<br/>一个 key 只有一个当前值"] --> Problem["多客户端并发读写<br/>会遇到读旧值、写冲突、半路失败"]
Problem --> Txn["Lab4 的事务视角<br/>一个 key 有多个版本<br/>还有锁、提交记录、回滚记录"]
顺序:MIT 6.5840 和 TinyKV / Lab1 / Lab2 / Lab3 / Lab3B / Lab4 / 面经索引。
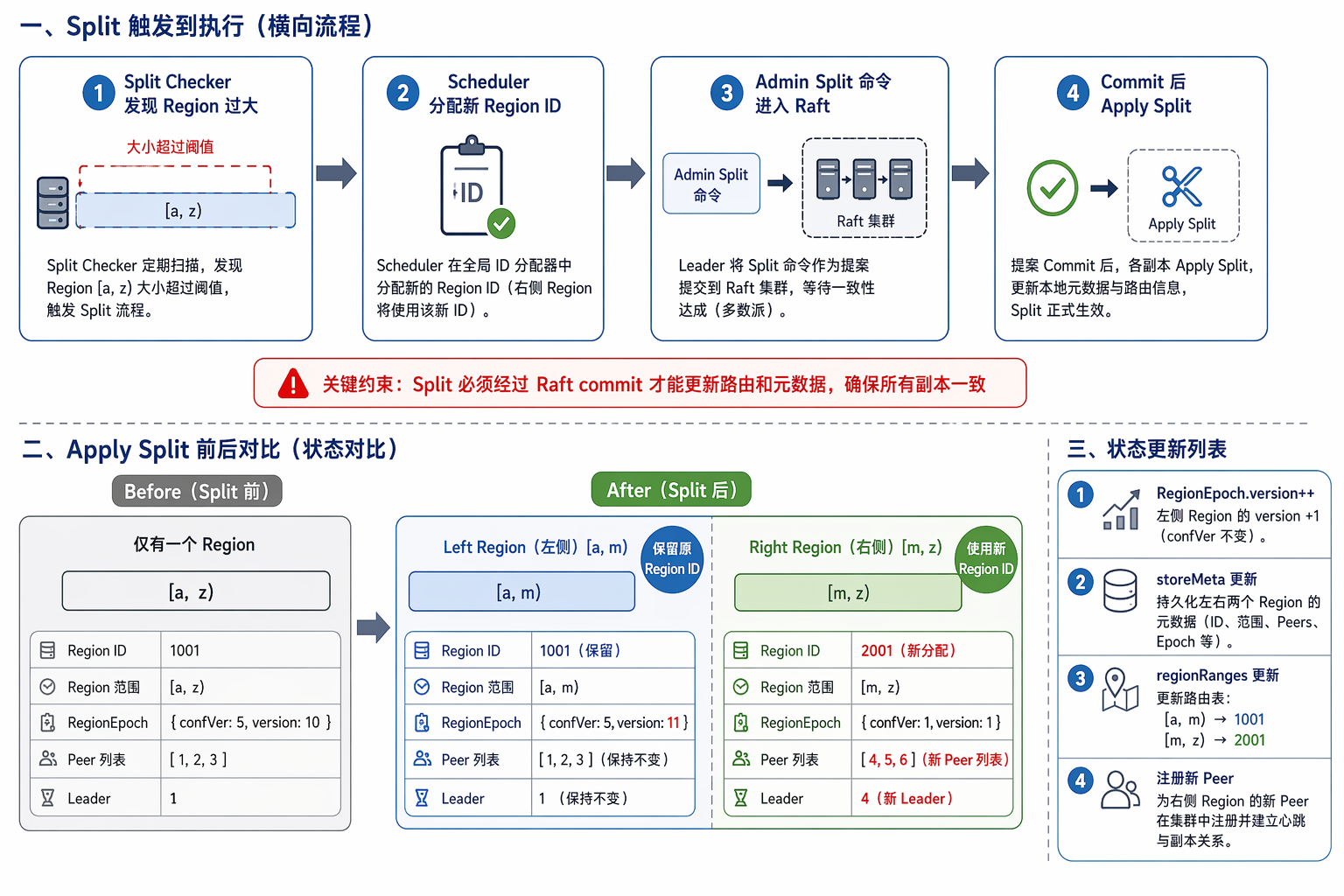
Lab3B 难在状态收敛。配置变更、用户请求、split 后的路由、scheduler heartbeat 都在改同一批 Region 元信息;如果顺序没有讲清楚,很多 bug 看起来像偶现,实际上是状态机边界没守住。
这份记录整理的是我们在 Lab3B 实现 Region Split、ChangePeer、snapshot recovery 相关逻辑时遇到的几个问题。它们表面上出现在不同测试里,但本质都和 raftstore 在 split/conf change 之后的状态收敛有关。
| 编号 | 问题 | 根因总结 | 典型现象 | 修复位置 |
|---|---|---|---|---|
| 1 | split 后 scheduler 短暂找不到右半边 region | split apply 后只立即上报了 left region,right region 依赖后续异步 heartbeat,导致 scheduler 暂时出现 range gap | panic: find no region for "3 00000000" |
applySplit 中同时上报 left/right |
| 2 | 被移除的 peer 继续 apply 后续 committed entries | RemoveNode 删除自己后 peer 已经 destroy,但同一个 Ready 中剩余 committed entries 仍被继续 apply,可能破坏 raft/apply 状态一致性 |
unexpected raft log index: lastIndex 0 < appliedIndex ... |
HandleRaftReady 每次 applyEntry 后检查 d.stopped |
| 3 | 用 left region 访问 right key 时没有稳定返回 KeyNotInRegion |
普通 KV 请求只在 apply 阶段检查 key range,请求已经进入 Raft 后才发现越界,错误返回受 commit/apply 时序影响 | TestOneSplit3B 中 expected KeyNotInRegion,但 header error 为 nil |
preProposeRaftCommand 对普通 KV 请求提前检查 key range |
顺序:MIT 6.5840 和 TinyKV / Lab1 / Lab2 / Lab3 / Lab3B / Lab4 / 面经索引。
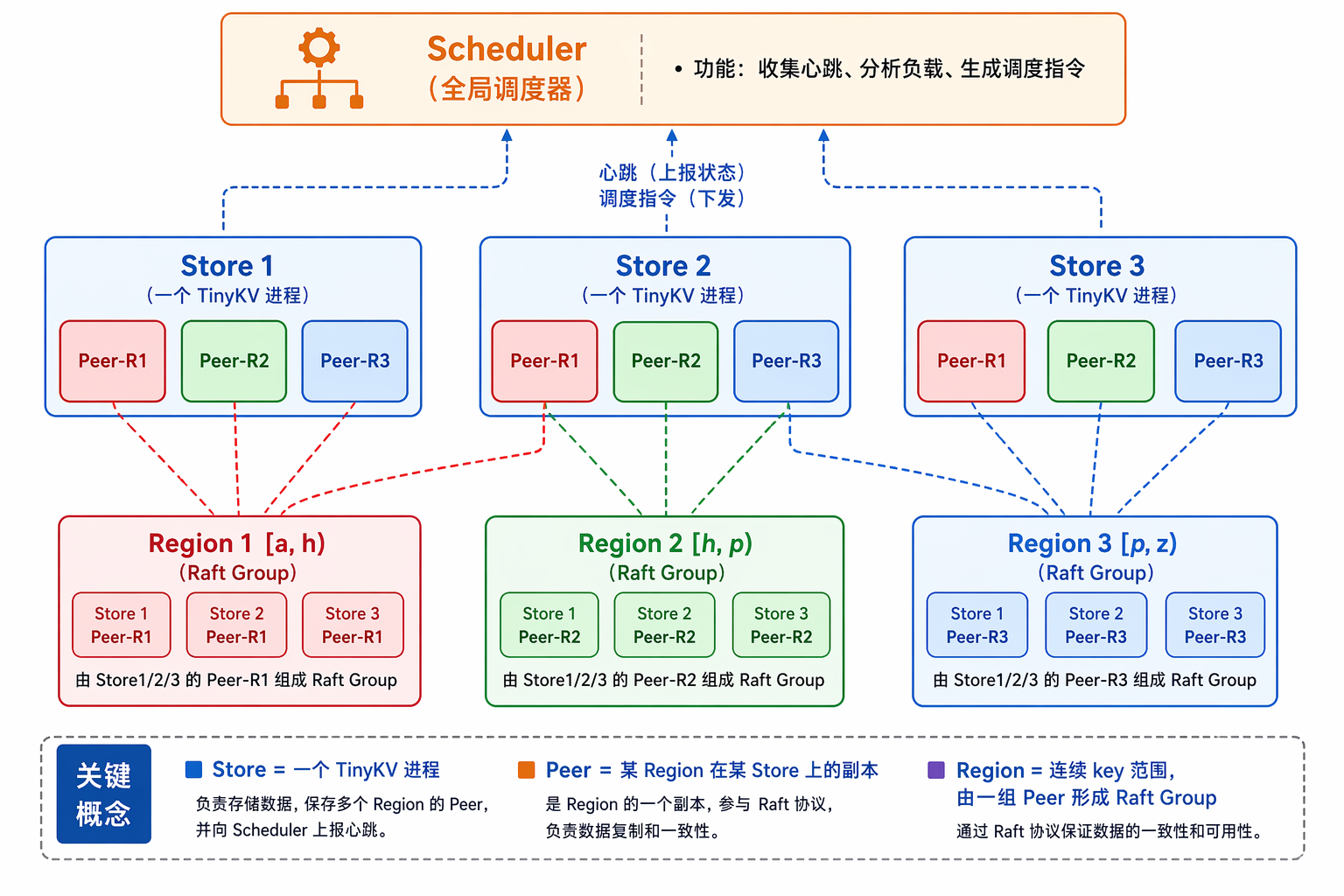
Lab3 开始才真正像一个分布式存储系统。单个 Raft group 只能让数据更可靠,不能让容量和吞吐横向扩展;Region 和 Multi-Raft 解决的是“把不同 key range 分给不同 Raft group”这件事。
官方页面:https://yunpengn.github.io/tinykv/doc/project3-MultiRaftKV.html
Lab3 要把“一个 Raft 组管理全部 key”,升级成“多个 Raft 组分别管理不同 key 范围”。
Lab2 是:
1 | 全部 key -> 一个 Region -> 一个 Raft 组 |
Lab3 变成:
1 | [a, h) -> Region 1 -> Raft 组 1 |
这样数据量大了以后,就可以把不同范围的数据分摊到不同节点上。
从 Lab2 到 Lab3,可以先看这张图:
graph LR
subgraph Lab2["Lab2:单 Raft 组"]
AllKeys["全部 key<br/>[空, 空)"] --> OneRegion["Region 1"]
OneRegion --> OneRaft["一个 Raft 组"]
end
subgraph Lab3["Lab3:Multi-Raft"]
R1["Region 1<br/>[空, h)"] --> G1["Raft 组 1"]
R2["Region 2<br/>[h, p)"] --> G2["Raft 组 2"]
R3["Region 3<br/>[p, 空)"] --> G3["Raft 组 3"]
end
OneRaft --> R1
OneRaft --> R2
OneRaft --> R3
Lab3 的目标不是“把 Raft 换掉”,而是让系统里同时跑很多个 Raft 组。每个 Raft 组只负责一段 key。
顺序:MIT 6.5840 和 TinyKV / Lab1 / Lab2 / Lab3 / Lab3B / Lab4 / 面经索引。
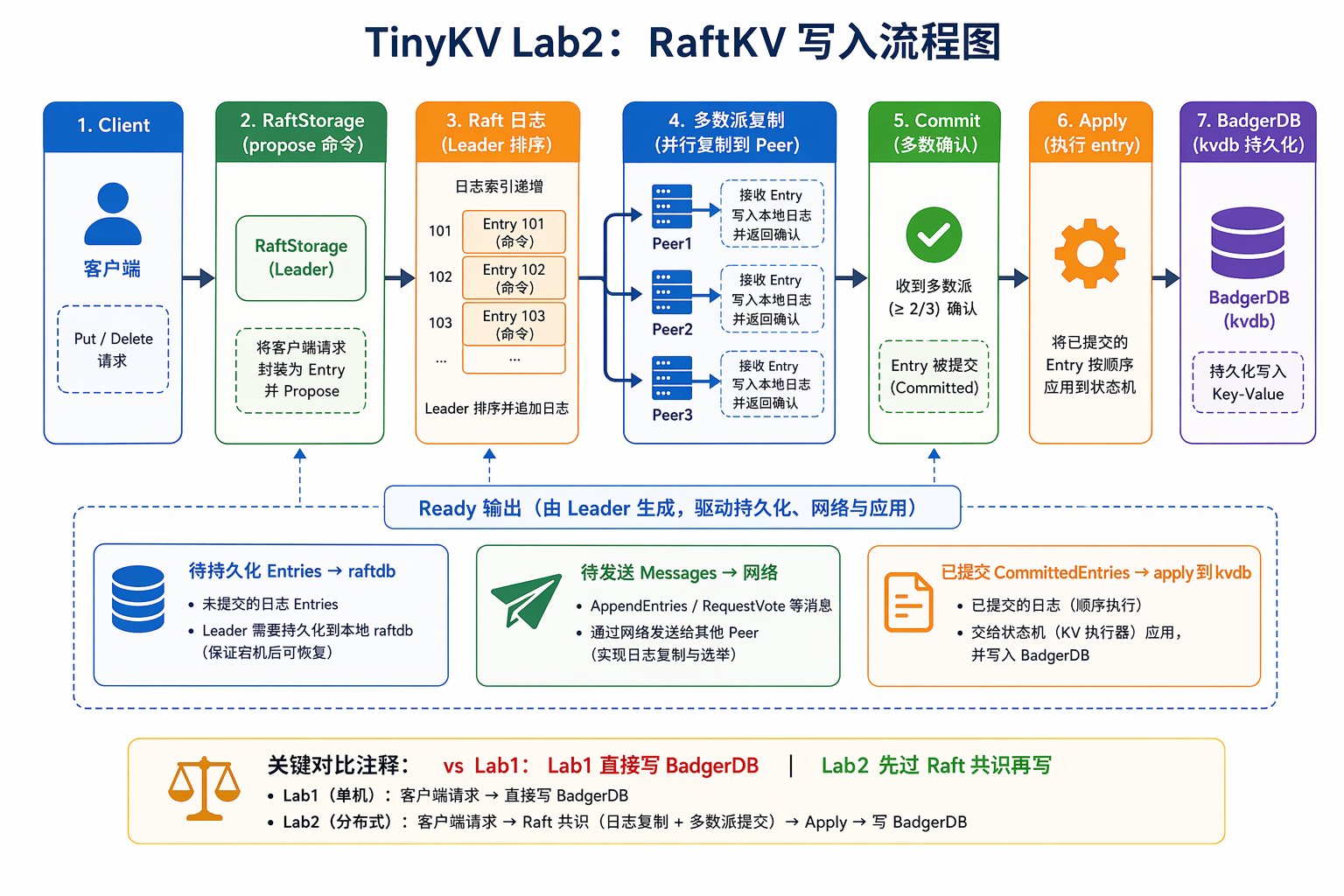
Lab2 的重点不是“多套一层 Raft”这么简单。真正要想明白的是:共识算法只负责排出一个确定顺序,上层还要把日志持久化、发消息、apply 和 callback 串起来。顺序错了,崩溃恢复时就会露馅。
官方页面:https://yunpengn.github.io/tinykv/doc/project2-RaftKV.html
Lab2 要把 Lab1 的单机 KV,升级成基于 Raft 的多副本 KV。
Lab1 是:
1 | 请求 -> 直接写本地 Badger |
Lab2 变成:
1 | 请求 -> 先写 Raft 日志 -> 多数副本确认 -> 再写 Badger |
更完整一点,写请求会走这条路:
1 | 客户端请求 |
这样做的目的很简单:只要大多数节点还活着,服务就能继续工作,而且多个副本的数据不会乱。
更直观地说,Lab2 解决的是 Lab1 的两个问题:
1 | 问题 1:只有一台机器,挂了就没服务。 |
Raft log 可以先理解成“操作流水账”:
1 | log[1] = Put name Tom |
BadgerDB 是执行流水账后的最终结果:
1 | name = Tom |
所以 Lab2 的关键不是“怎么把 value 写进硬盘”,而是:
1 | 所有副本怎样先同意这条操作排在第几位, |
最近把 MIT 6.5840 和 TinyKV 都重新梳理了一遍。它们看起来都在写 KV、Raft、分片和容错,但真正做下来会发现,二者的训练目标很不一样。
MIT 6.5840 更像分布式系统正确性的训练营。它关心的是:在 RPC 丢包、乱序、重试、网络分区、节点重启这些条件下,系统怎样还能给出正确结果。TinyKV 更像分布式数据库存储层的缩小版。它关心的是:数据如何落到本地存储,Raft 如何接入真实的 raftstore,Region 如何分裂和调度,事务如何通过 MVCC 和 Percolator 协议实现。
一句话概括:
1 | MIT 6.5840 训练的是分布式系统底层正确性。 |
顺序:MIT 6.5840 和 TinyKV / Lab1 / Lab2 / Lab3 / Lab3B / Lab4 / 面经索引。
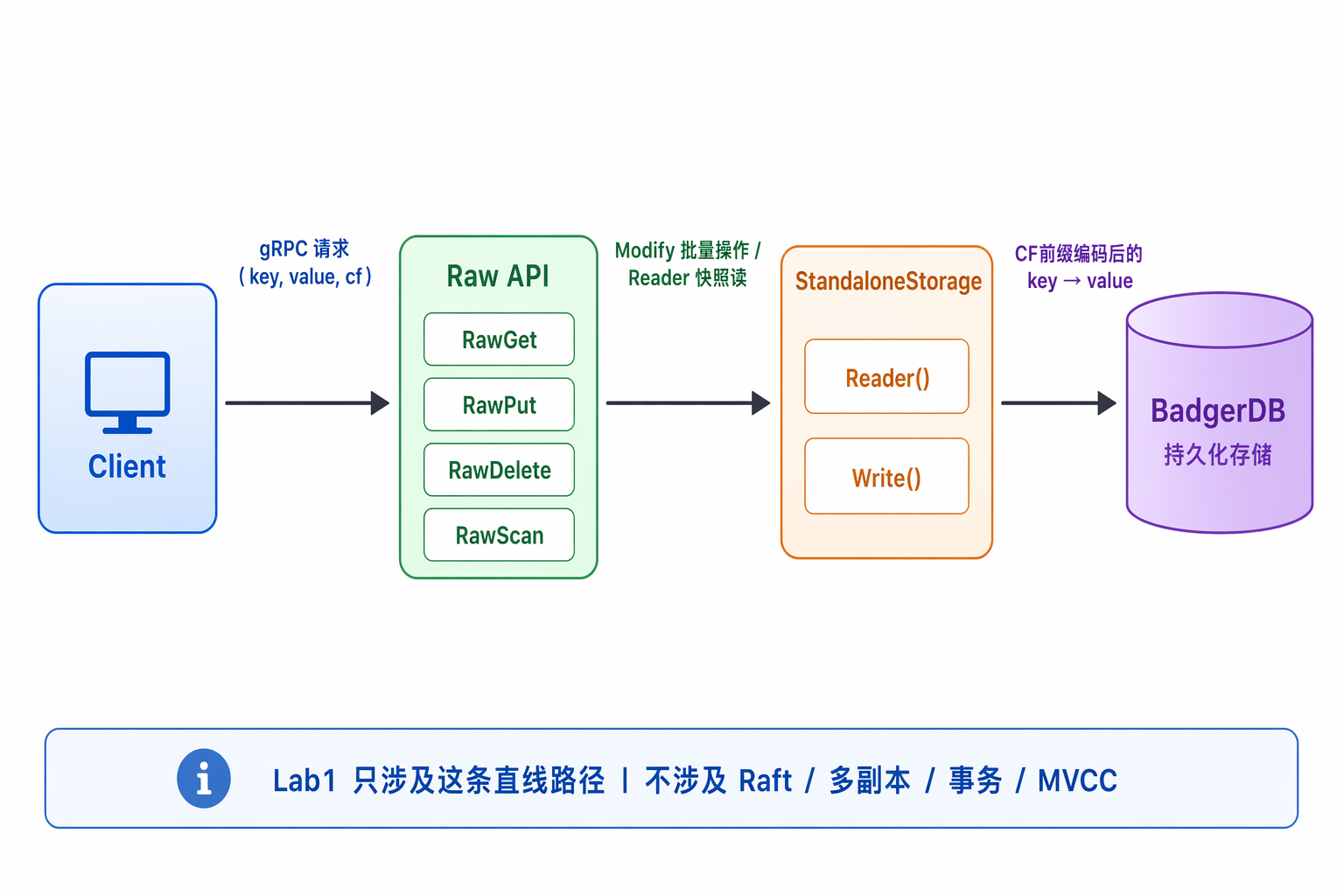
Lab1 看起来轻,但它决定了后面几层怎么和本地存储说话。先把 Raw API、Storage.Reader/Write 和 CF 这几个点讲清楚,后面的 Raft apply 和 MVCC 才有地方落。
官方页面:https://yunpengn.github.io/tinykv/doc/project1-StandaloneKV.html
Lab1 要做一个单机版 KV 服务。
它还没有 Raft、没有多副本、没有事务。客户端发 RawGet、RawPut、RawDelete、RawScan 请求,服务端直接读写本地的 Badger 数据库。
顺序:Lab1 MapReduce / Lab2 KV Server / Lab3 Raft / Lab4 KV over Raft / Lab5 Sharded KV
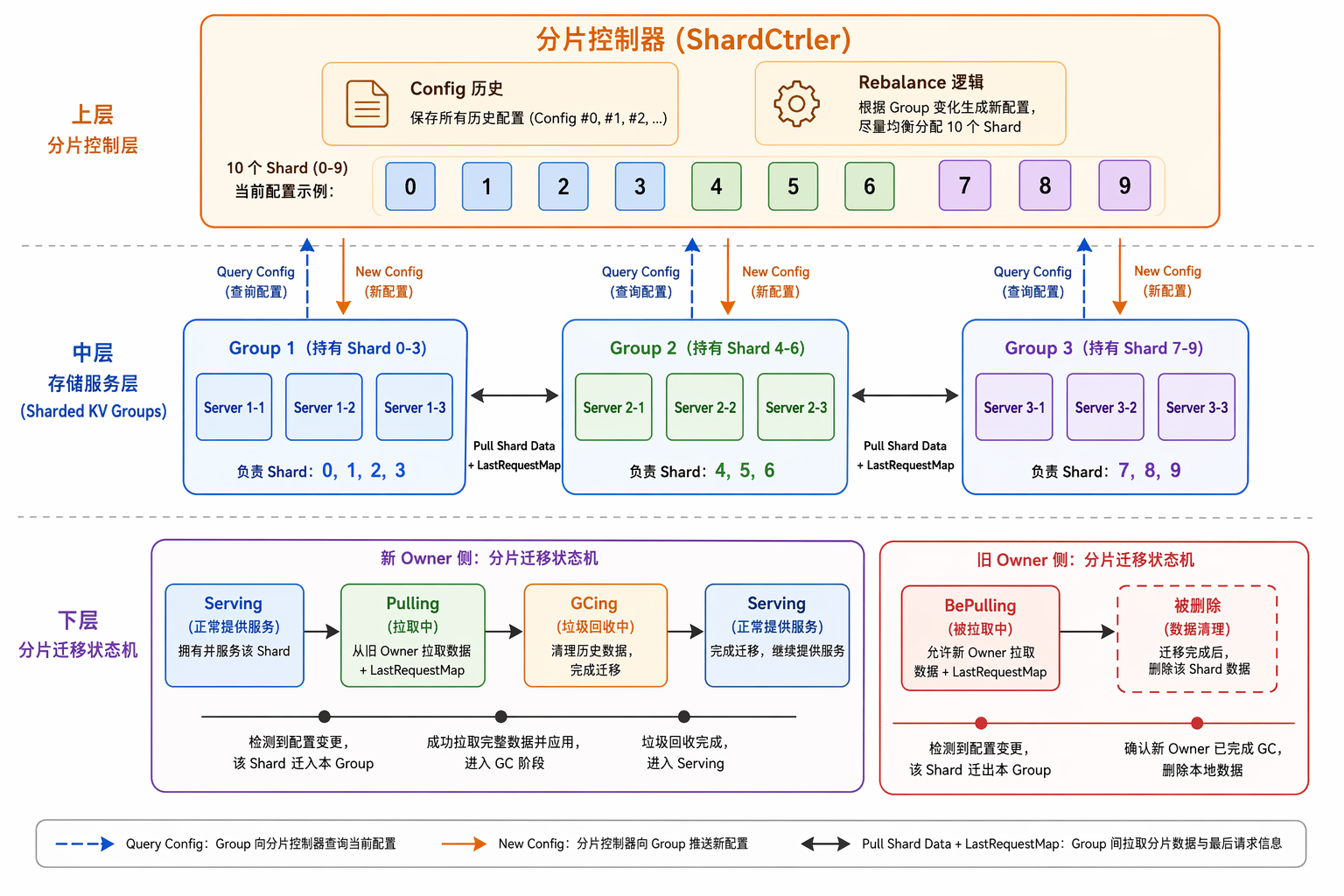
Lab5 把单一 Raft Group 扩展为多个 Raft Group,每个 Group 负责一部分 Key(分片),并且支持动态迁移——加减节点时数据能自动搬家。
顺序:Lab1 MapReduce / Lab2 KV Server / Lab3 Raft / Lab4 KV over Raft / Lab5 Sharded KV
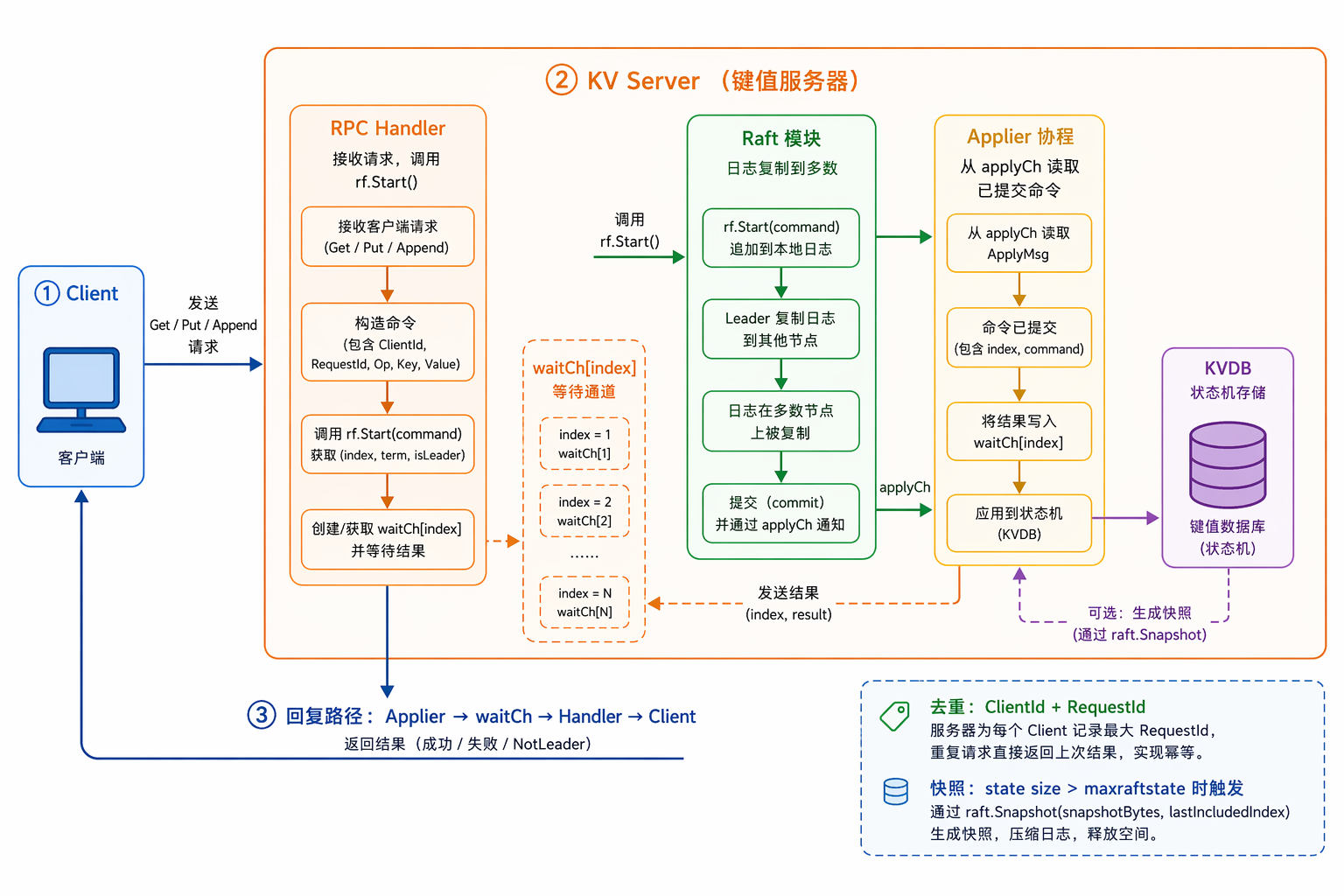
Lab4 在 Raft 之上搭建一个线性化的 KV 服务——Client 看到的效果就像操作一台机器,但背后是多台机器在同步。
顺序:Lab1 MapReduce / Lab2 KV Server / Lab3 Raft / Lab4 KV over Raft / Lab5 Sharded KV
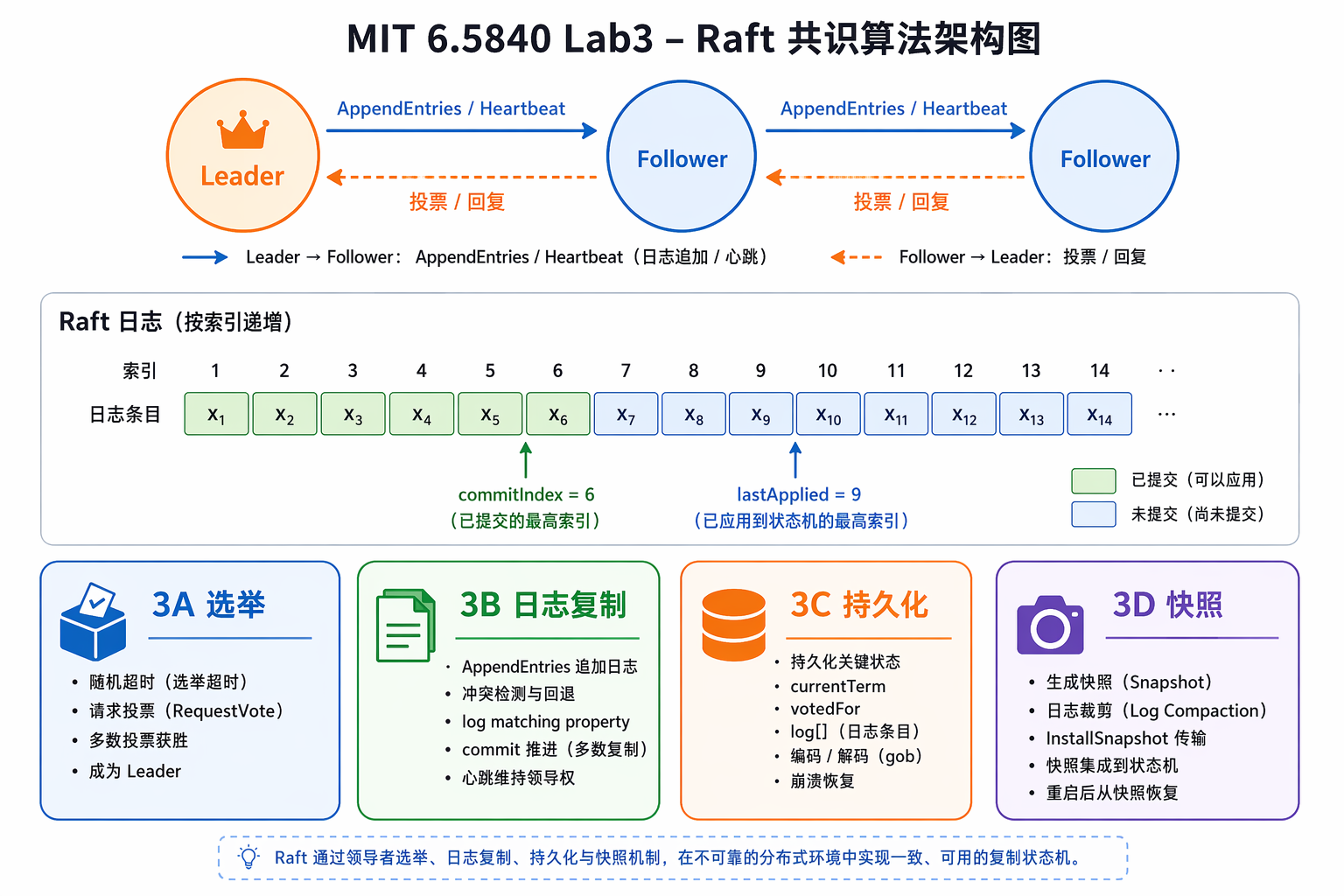
Lab3 实现完整的 Raft 共识算法——让多台机器对一组操作的顺序达成一致,即使部分机器挂掉也能继续工作。