MIT 6.5840 Lab1:MapReduce
顺序:Lab1 MapReduce / Lab2 KV Server / Lab3 Raft / Lab4 KV over Raft / Lab5 Sharded KV
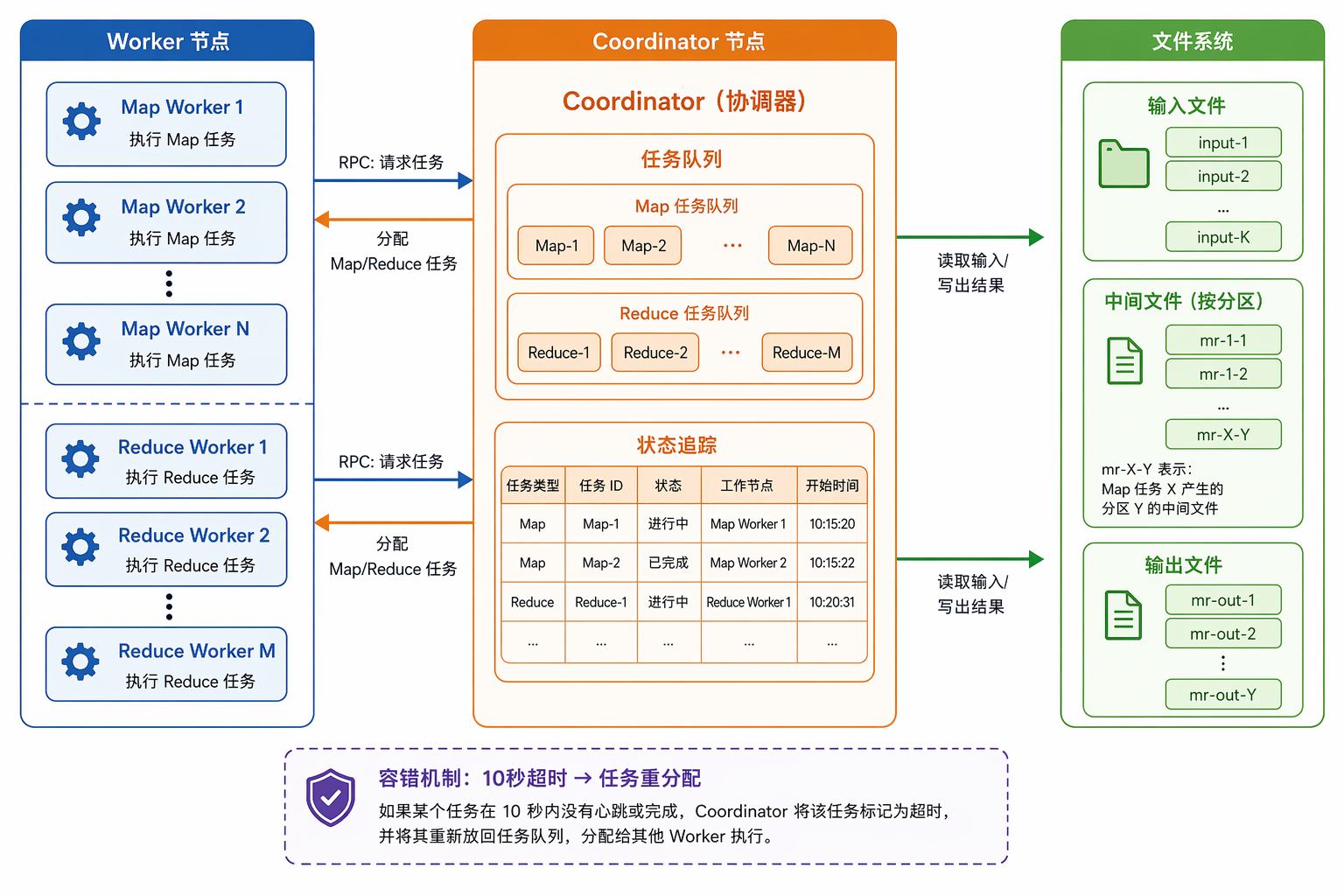
一句话总结
Lab1 实现一个分布式 MapReduce 框架:一个 Coordinator 协调多个 Worker,把大任务拆成小任务并行执行,还要处理 Worker 挂掉的情况。
为什么要做这个
MapReduce 是理解分布式计算的第一步。它回答一个核心问题:如何把一个大的计算任务分给多台机器去做,还能容忍某些机器挂掉?
你学到的思维模式——任务分发、超时检测、原子写入——在后面每个 Lab 都会反复出现。
核心角色
Coordinator(协调器)
Coordinator 是”老板”,它不干活,只管分配和追踪:
1 | type Master struct { |
它暴露 RPC 接口让 Worker 调用:
AllocateTask:Worker 来要任务,返回任务类型和文件信息ReceiveFinishedMap/Reduce:Worker 报告完成
Worker(工作节点)
Worker 是”打工人”,它的生命周期就是一个循环:
1 | 请求任务 → 执行 → 报告完成 → 请求下一个任务 → ... |
执行流程详解
Map 阶段
1 | 输入文件 pg-*.txt |
每个 Map Worker:
- 读取分配到的输入文件
- 调用用户的
mapf函数产生 key-value 对 - 按
hash(key) % nReduce把结果分成 nReduce 个桶 - 写入中间文件
mr-X-Y(X 是 Map 任务号,Y 是桶号)
Reduce 阶段
1 | 中间文件 mr-*-Y(所有属于桶 Y 的文件) |
每个 Reduce Worker:
- 收集所有
mr-*-Y文件(同一桶号的所有 Map 输出) - 按 key 排序
- 对相同 key 的所有 value 调用用户的
reducef函数 - 写入最终输出
mr-out-Y
关键设计决策
1. 容错:10 秒超时重分配
Worker 随时可能挂掉。Coordinator 的策略很简单:
1 | go func(taskId int) { |
分配任务时启动一个 goroutine,10 秒后如果任务还没完成,就标记为未分配,下次有 Worker 来要任务时会重新分配。
2. 原子写入:防止部分输出
如果 Worker 写到一半挂了,文件里只有半截数据怎么办?答案是先写临时文件,再原子重命名:
1 | tmpFile, _ := os.CreateTemp("", "mr-tmp-*") |
os.Rename 在 Unix 上是原子的——要么整个文件出现,要么什么都没有。不存在”半个文件”的状态。
3. 阶段隔离:Map 全部完成后才开始 Reduce
Coordinator 维护阶段状态:
mapfinished < len(files)→ 只分配 Map 任务mapfinished == len(files)且reducefinished < nReduce→ 分配 Reduce 任务- 全部完成 → 返回 Done
这确保 Reduce Worker 不会读到不完整的中间数据。
我的实现要点
回看 src/mr/ 目录下的代码:
| 文件 | 职责 |
|---|---|
coordinator.go |
Coordinator 逻辑:任务分配、超时检测、完成追踪 |
worker.go |
Worker 循环:请求→执行→报告 |
rpc.go |
RPC 请求/响应结构体定义 |
整个 Lab 代码量不大(~200 行核心逻辑),但建立了后续所有 Lab 的基础思维:无状态 Worker + 有状态 Coordinator + 幂等操作 + 超时容错。
面试常问
- MapReduce 如何容错? 超时重分配 + 原子写入 + 幂等 Reduce
- 为什么 Map 和 Reduce 不能并行? Reduce 依赖 Map 的全部中间输出
- 中间文件命名 mr-X-Y 的含义? X=Map任务号, Y=Reduce分区号
- 瓶颈在哪? 单 Coordinator 是瓶颈,所有调度决策都经过它