顺序:Lab1 MapReduce / Lab2 KV Server / Lab3 Raft / Lab4 KV over Raft / Lab5 Sharded KV
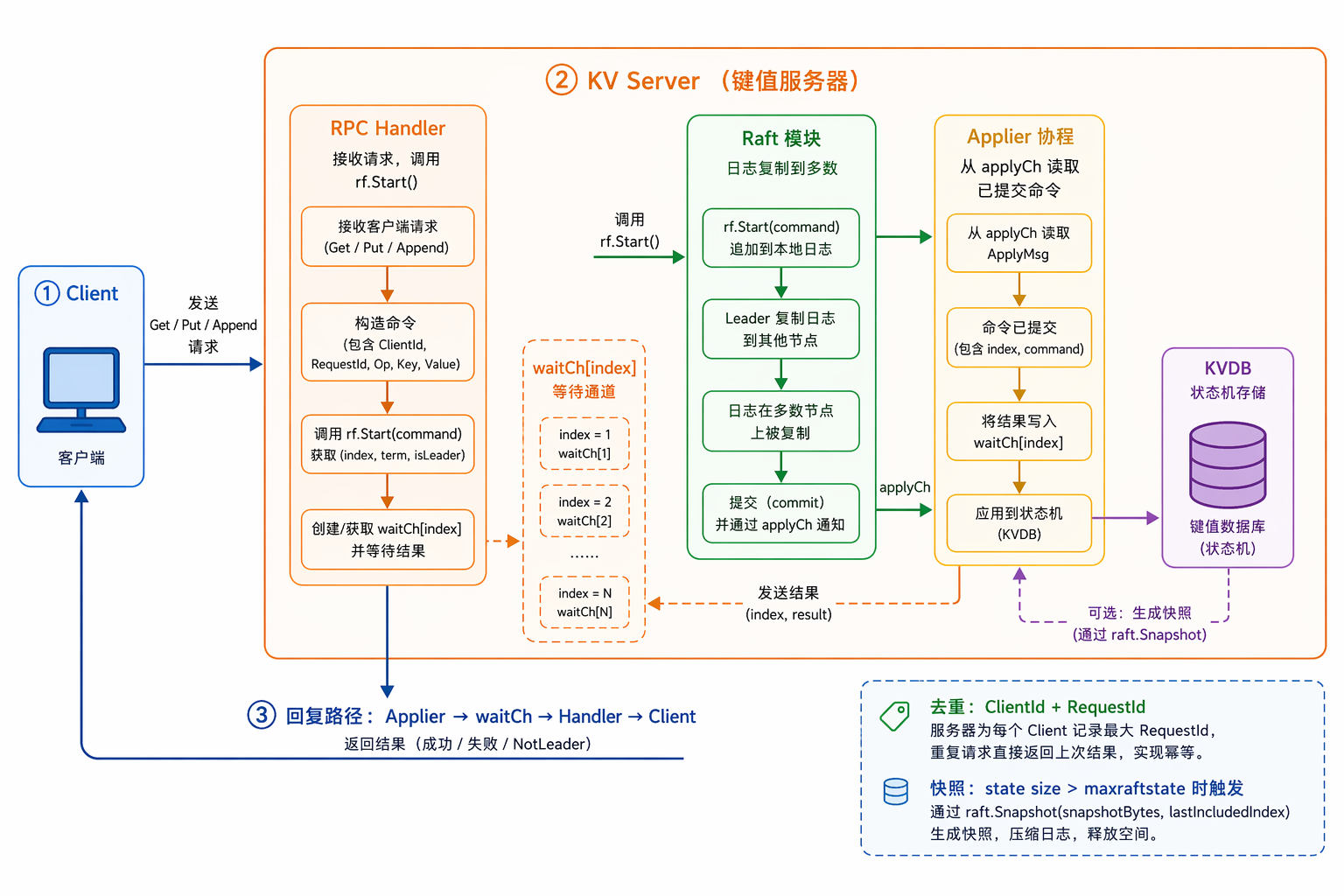 Lab4 的请求路径:Client → RPC Handler → Raft → Apply → KVDB → 回复 Client。
Lab4 的请求路径:Client → RPC Handler → Raft → Apply → KVDB → 回复 Client。
一句话总结
Lab4 在 Raft 之上搭建一个线性化的 KV 服务——Client 看到的效果就像操作一台机器,但背后是多台机器在同步。
为什么要做这个
Lab3 给了我们一个”日志一致”的引擎,但它只管日志顺序,不管业务。Lab4 要把它变成真正能用的 KV 服务:
- Client 发 Get/Put/Append → 多数副本确认 → 回复 Client
- Leader 挂了自动切换,Client 无感知
- 日志太长了自动做快照
核心架构:两个世界的桥梁
Lab4 的本质就是在”KV 业务世界”和”Raft 共识世界”之间搭一座桥:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| ┌─────────────────────────────────────────────┐
│ KV Server │
│ │
│ RPC Handler ──→ rf.Start(op) ──→ Raft 日志 │
│ │ │ │
│ │ 等待... │ 复制 │
│ │ ▼ │
│ │ applyCh │
│ │ │ │
│ waitCh[idx] ←── Applier ←──────────┘ │
│ │ │ │
│ ▼ ▼ │
│ 回复 Client KVDB │
└─────────────────────────────────────────────┘
|
Channel-per-Index 模式
这是 Lab4 最精妙的设计。问题是:RPC Handler 怎么知道 Raft 什么时候把自己的命令 apply 了?
答案:给每个 log index 一个 channel,Handler 等在上面,Applier apply 后往里面发信号。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| type KVServer struct {
KVDB map[string]string
waitChMap map[int]chan *Op
LastRequestMap map[int64]int64
}
func (kv *KVServer) PutAppend(args *PutAppendArgs, reply *PutAppendReply) {
op := Op{Key: args.Key, Value: args.Value, Op: args.Op,
ClientId: args.ClientId, RequestId: args.RequestId}
index, term, isLeader := kv.rf.Start(op)
if !isLeader {
reply.Err = ErrWrongLeader
return
}
ch := kv.getWaitCh(index)
select {
case appliedOp := <-ch:
if appliedOp.ClientId == op.ClientId && appliedOp.RequestId == op.RequestId {
reply.Err = OK
} else {
reply.Err = ErrWrongLeader
}
case <-time.After(500 * time.Millisecond):
reply.Err = ErrWrongLeader
}
kv.deleteWaitCh(index)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
func (kv *KVServer) applier() {
for msg := range kv.applyCh {
op := msg.Command.(Op)
if !kv.isInvalidRequest(op.ClientId, op.RequestId) {
switch op.Op {
case "Put":
kv.KVDB[op.Key] = op.Value
case "Append":
kv.KVDB[op.Key] += op.Value
}
kv.LastRequestMap[op.ClientId] = op.RequestId
}
if ch, ok := kv.waitChMap[msg.CommandIndex]; ok {
ch <- &op
}
}
}
|
为什么 Get 也要走 Raft?
线性化要求:读操作必须读到最新的已提交数据。
如果 Get 不走 Raft 直接读本地:
- 旧 Leader 被网络隔离,它不知道自己已经不是 Leader 了
- 新 Leader 已经处理了新的写入
- Client 从旧 Leader 读到过期数据 → 违反线性化
解决方案简单粗暴:Get 也作为一条日志走 Raft。当它被 apply 时,说明此时此刻这个节点确实是 Leader 且数据是最新的。
去重:和 Lab2 一样的套路
1
2
3
4
5
6
|
func (kv *KVServer) isInvalidRequest(clientId, requestId int64) bool {
lastId, ok := kv.LastRequestMap[clientId]
return ok && requestId <= lastId
}
|
注意:去重只对 Put/Append 生效。Get 是幂等的,重复读没关系。
Lab4B:快照
当 Raft 日志太大时(persister.RaftStateSize() >= maxraftstate),做一个快照:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func (kv *KVServer) checkSnapshot(index int) {
if kv.maxraftstate == -1 { return }
if kv.persister.RaftStateSize() >= kv.maxraftstate {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(kv.KVDB)
e.Encode(kv.LastRequestMap)
kv.rf.Snapshot(index, w.Bytes())
}
}
|
快照包含什么?
KVDB:全部 KV 数据LastRequestMap:去重表
这两个加在一起就是完整的状态机状态。恢复时直接加载,不需要从头 replay 日志。
Client 的设计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| type Clerk struct {
servers []*labrpc.ClientEnd
leaderId int
clientId int64
requestId int64
}
func (ck *Clerk) PutAppend(key, value, op string) {
ck.requestId++
args := &PutAppendArgs{
Key: key, Value: value, Op: op,
ClientId: ck.clientId, RequestId: ck.requestId,
}
for {
reply := &PutAppendReply{}
ok := ck.servers[ck.leaderId].Call("KVServer.PutAppend", args, reply)
if ok && reply.Err == OK {
return
}
ck.leaderId = (ck.leaderId + 1) % len(ck.servers)
}
}
|
- 缓存
leaderId 避免每次都轮询
- 失败时轮转到下一个 server
- 同一个请求的所有重试使用相同的 requestId
关键 Edge Case
1. Log 被覆盖
Leader A 在 index=5 放了 Client X 的命令,但还没 commit 就挂了。新 Leader B 在 index=5 放了 Client Y 的命令。A 恢复后收到 apply,index=5 变成了 Y 的命令。
解决:Handler 收到通知后,验证 appliedOp.ClientId == myOp.ClientId,不匹配就返回 ErrWrongLeader。
2. Applier 发信号时 Handler 已经超时走了
Channel 是 buffered(size=1),所以 Applier 写入不会阻塞。Handler 超时后 channel 被删除,下次 apply 时找不到就跳过。
3. 重复 Apply
网络分区恢复后,旧 Leader 的 Raft 可能 apply 一些已经在新 Leader 上 apply 过的命令。LastRequestMap 确保不会重复执行。
整体数据流总结
1
2
3
4
5
6
7
8
9
10
11
12
| ┌────────┐ ┌─────────────────────────────────────────────┐
│ Client │───→│ Handler: rf.Start(op) │
│ │ │ ↓ │
│ │ │ Raft: replicate to majority │
│ │ │ ↓ │
│ │ │ applyCh → Applier: execute + notify waitCh │
│ │←───│ │
└────────┘ └─────────────────────────────────────────────┘
去重保证:at-most-once
快照保证:bounded memory
线性化保证:所有操作(含 Get)经过 Raft 排序
|